See if you get quoted
before you publish the page.
Before you publish, Ranko runs the page through ChatGPT, Claude, Perplexity, and Gemini to see if it gets quoted.
From draft to publish confidence in 4 steps
Pick the article ready to ship. Ranko runs it through four engines with five questions: a verdict per engine.
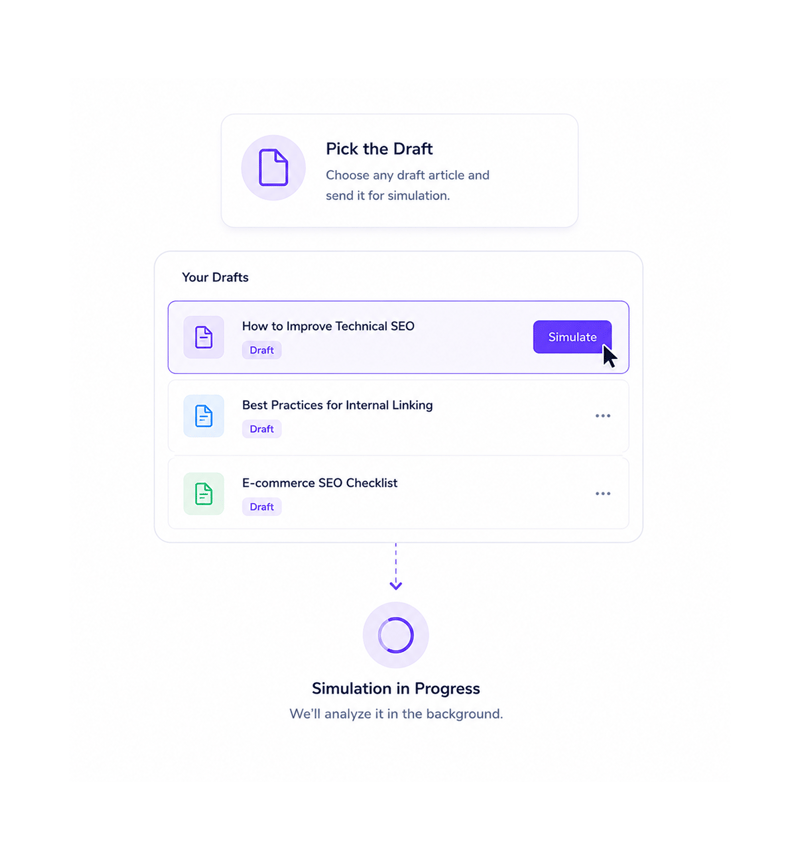
Pick the Draft
Pick the article ready to ship
Any draft in Ranko can go into the simulator: articles from Article Writer, pages from Page Refresher, imported content. Articles scheduled on the calendar can be simulated before their date. The team picks one, hits simulate, and the rest runs.
- Any Draft
- Or Scheduled
- From Article Writer
- From Page Refresher
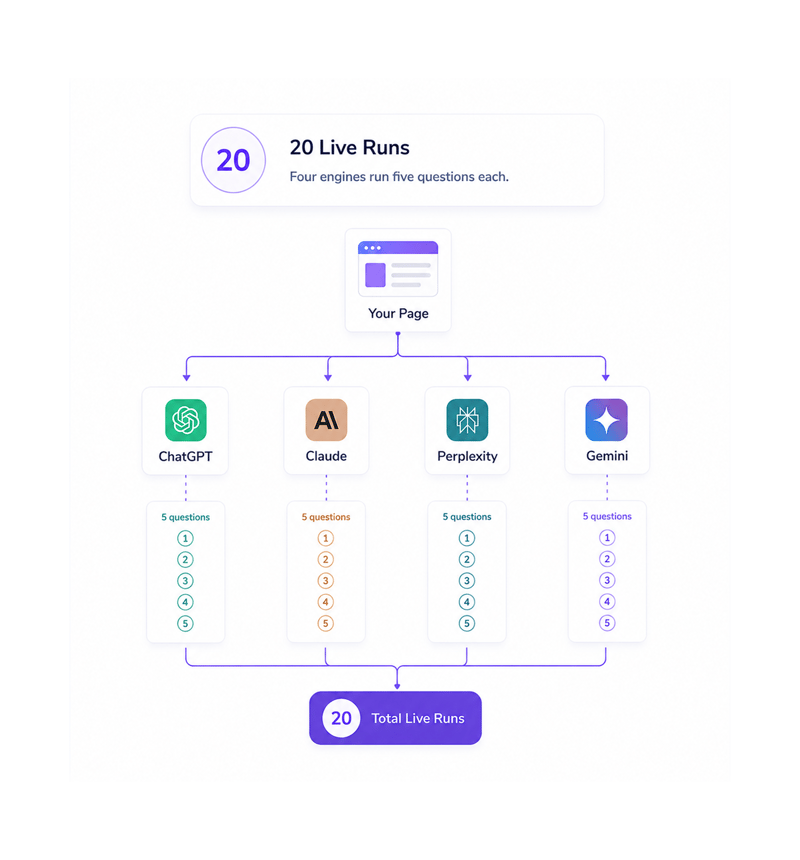
20 Live Runs
Four engines run five questions each
Ranko runs the page through ChatGPT, Claude, Perplexity, and Gemini with the five most relevant questions: twenty live runs. Each engine asks each question independently and records whether the page was quoted.
- ChatGPT
- Claude
- Perplexity · Gemini
- 20 Total Runs

The Verdict
Quoted or not, what was used, who won instead
For every engine and question, the simulation returns three things. Was your page quoted. If yes, the exact passage lifted. If no, which competitor was picked. Three pieces times twenty runs is sixty data points.
- Quoted Yes/No
- Exact Passage
- Competitor Named
- 60 Data Points
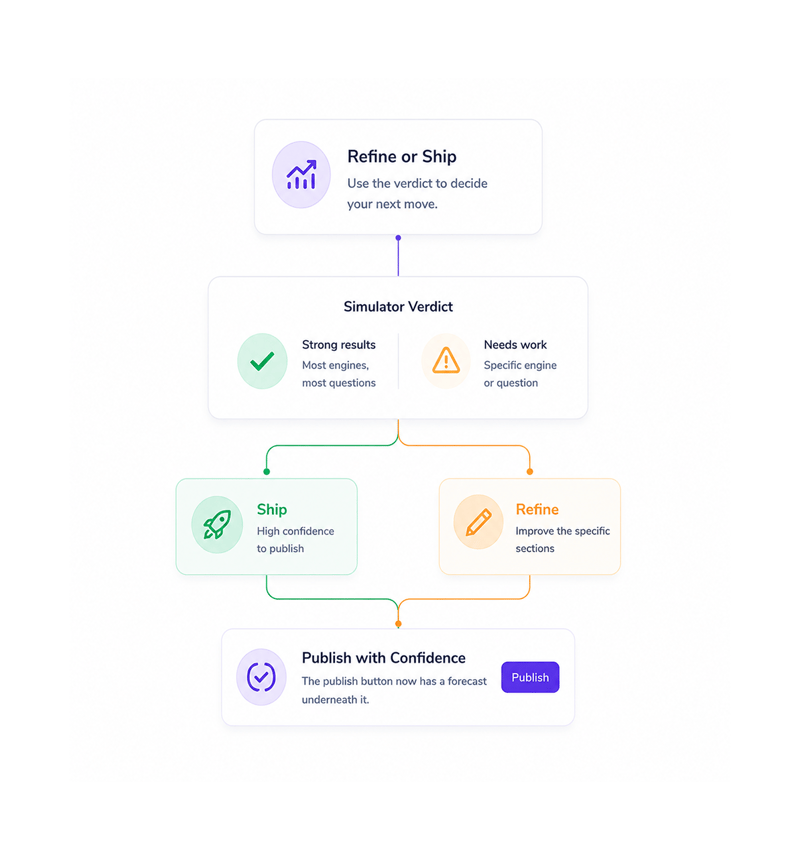
Refine or Ship
Refine before publish, or ship with confidence
With the verdict in hand, the team decides. Strong results across most engines mean publish with confidence. Weaker results show which sections need refining: the passage a competitor won. Refine and re-run.
- Refine Specific Sections
- Re-Simulate
- Ship at Threshold
- Informed Publish
Six reasons publishing stops being a leap of faith
Once a team runs every draft through four engines with five real questions before publishing, and sees what got quoted, this changes first.

The publish button stops being a guess
Publishing with no pre-flight check ships into the dark. The simulator makes the call informed: twenty live results show which sections earn quotes.

Per engine, per question, per passage
An overall forecast is useful. A per engine, per question, per passage forecast is actionable. The team sees which engines and sentences win.

Knowing which competitor won is the strategic answer
The simulator does not just say the article lost. It names the competitor picked, by domain and page, turning a failure into a roadmap.

Refine before live, not in production
Refining in production means readers saw the flawed version first. Pre publish refinement makes the first live version the best one.

Four engines mean four chances to be picked
An article that wins on ChatGPT but loses on Perplexity is a partial win. Three of four engines is a strong publish; all four lost needs a pass.

The forecast turns the team into AEO scientists
Teams running the simulator regularly spot patterns: which structural moves earn quotes, which headings win on which engines. An AEO learning loop.
The publish button stops being a guess
Publishing with no pre-flight check ships into the dark. The simulator makes the call informed: twenty live results show which sections earn quotes.
Per engine, per question, per passage
An overall forecast is useful. A per engine, per question, per passage forecast is actionable. The team sees which engines and sentences win.
Knowing which competitor won is the strategic answer
The simulator does not just say the article lost. It names the competitor picked, by domain and page, turning a failure into a roadmap.
Refine before live, not in production
Refining in production means readers saw the flawed version first. Pre publish refinement makes the first live version the best one.
Four engines mean four chances to be picked
An article that wins on ChatGPT but loses on Perplexity is a partial win. Three of four engines is a strong publish; all four lost needs a pass.
The forecast turns the team into AEO scientists
Teams running the simulator regularly spot patterns: which structural moves earn quotes, which headings win on which engines. An AEO learning loop.




15300+
Teams shipping with informed publish confidence, not hopeful publish guesses
Built for teams who refuse to ship and pray
Founders, content leads, search and AEO specialists, editors, agencies, SaaS growth teams, and ecommerce operators all use Ranko's AI Mention Simulator as the pre publish layer that turns shipping into an informed choice.
Engines
Questions
Detail
Forecast
Live runs across 4 engines with 5 questions
Ranko runs the article through ChatGPT, Claude, Perplexity, and Gemini with the five most relevant questions: twenty live runs. Each runs alone, since averaging hides engine intelligence.
Everything the simulator ships with
A complete pre publish forecast toolkit in the same AEO platform you use. Live four engine runs, five questions, refine loop.

Live Pre Publish Runs
Every simulation is a live run against the four AI engines, not a static prediction. The team sees what they actually say.

Four Engine Coverage
ChatGPT, Claude, Perplexity, and Gemini all run independently and behave differently. The team sees where it wins and loses.

5 Most Relevant Questions
Ranko runs the five questions readers are most likely to ask, drawn from AI Question Mining, so you test real prompts.

Exact Quoted Passage
When the article is quoted, the simulator returns the exact passage lifted. The team sees which block worked and doubles down.

Competitor Picked Detection
When the article is not quoted, the simulator names the competitor picked: domain, page, passage. A failure becomes a roadmap.

Refine and Re Simulate Loop
The team can refine and re-run as often as needed before publishing. No limit, no penalty; it ships when the verdict earns trust.
Everything you need to know
Common questions about how the simulation runs, the five questions, and what counts as quoted.