One number per topic.
The size of your open door.
Ranko asks all four AI assistants each topic and scores how open the citation door is, zero to one hundred.

From topic to a single score in 4 steps
Ranko probes each topic across ChatGPT, Claude, Perplexity, and Gemini, then scores it zero to one hundred.
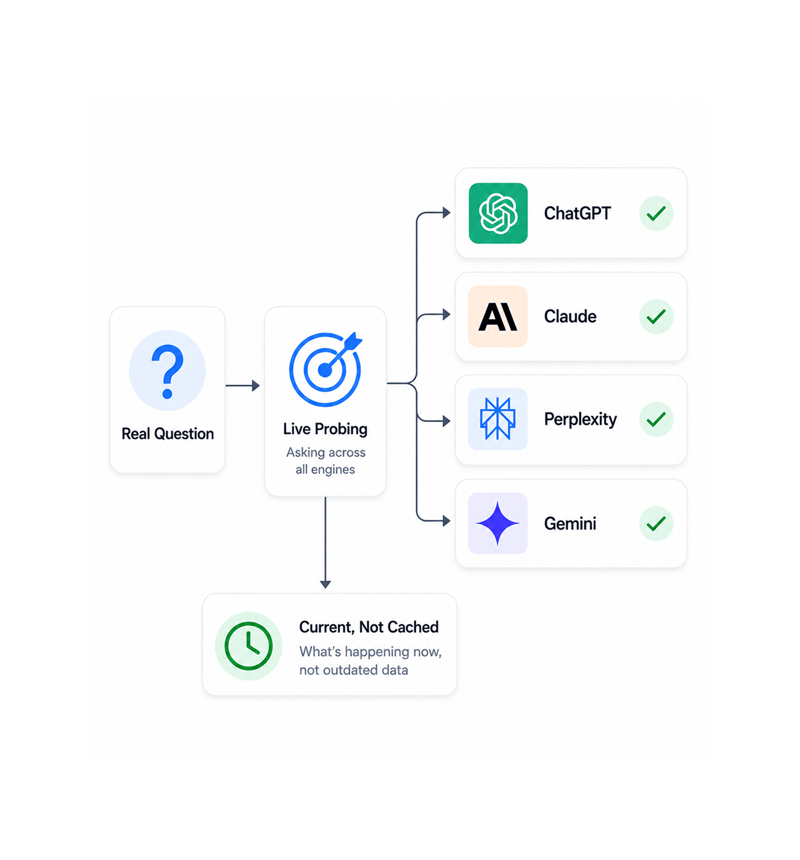
Live Probing
Ranko asks the question, for real
For every topic, Ranko asks the question to ChatGPT, Claude, Perplexity, and Gemini as a real user would. Not a stale keyword volume, but a live probe capturing what each engine says right now.
- Live Probing
- Real Questions Asked
- All 4 Engines
- Current, Not Cached
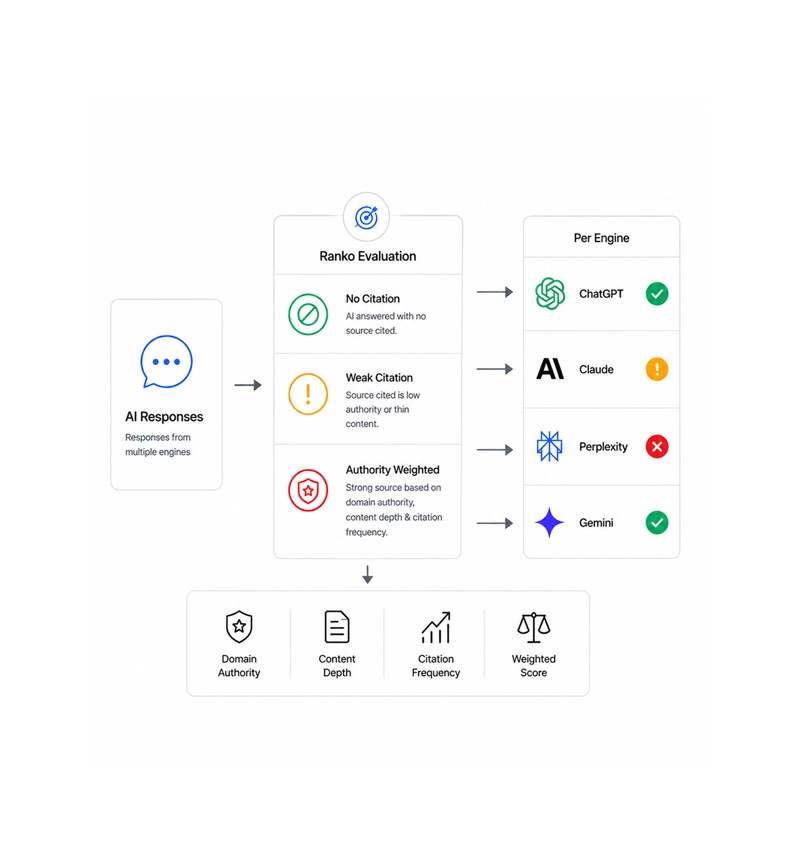
Citation Measurement
The answers get measured carefully
For every response, Ranko checks two things: did the engine cite anyone, and was the source strong or weak. No citation is a wide open door; a weak one you can push through. Each is weighed by domain authority and depth.
- No Citation Detection
- Weak Citation Detection
- Authority Weighted
- Per Engine
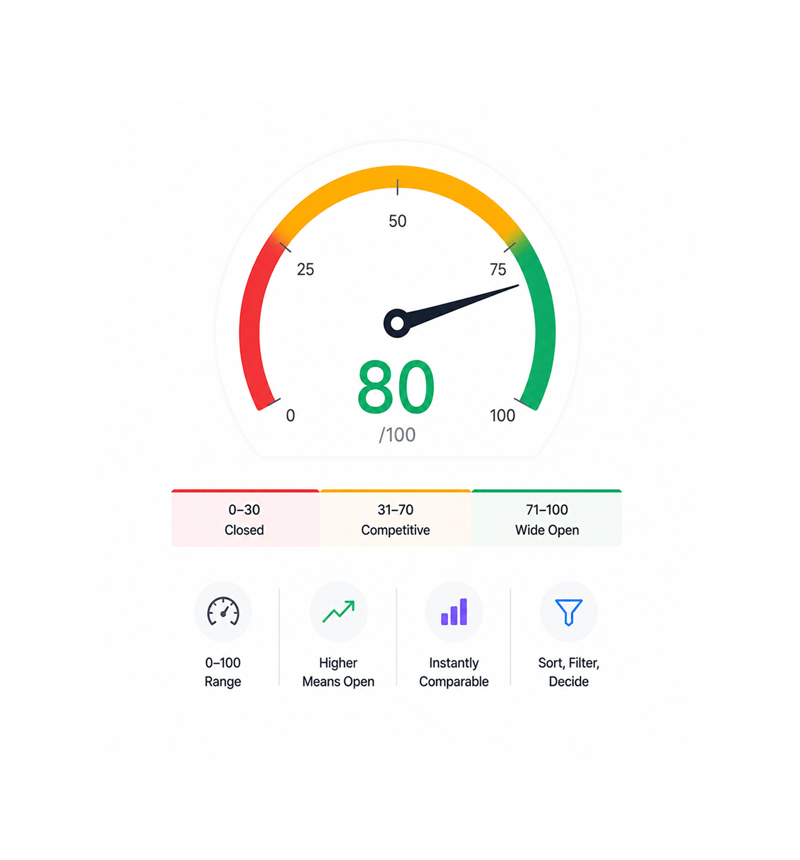
The 0–100 Score
One number per topic, zero to one hundred
The four engines compress into one number, zero to one hundred. Eighty means wide open, most engines answered blank or cited weak sources. Twenty means strong authorities own it. One number, instantly comparable, ready to drive a decision.
- 0–100 Range
- Higher Means Open
- Instantly Comparable
- Sort, Filter, Decide

Prioritisation Currency
Score the list, pick the winners
Sort the topic list by Opportunity Score and prioritisation solves itself. The topics on top are where the door is widest open and a strong piece of content has the highest chance of taking the citation. Point to the score and move on.
- Sort by Score
- Top Equals Open
- Decision Compression
- Argument Ends
Six reasons the open door is the only thing worth chasing
Once a team has one score per topic showing how open the door is now, arguing about what to publish next on gut feel stops being acceptable.

A live measurement, not a static guess
The score reflects what the engines do now, not what a keyword database thought six months ago. Live probing keeps the team on the current citation landscape.

No citation means an open door
When an engine answers without citing anyone, the slot is genuinely open and a strong answer can take it. The score surfaces these without digging.

Weak citations mean a door you can push through
When engines cite only weak competitors with thin authority, it is nearly as good as no citation. A strong answer can displace that placeholder fast.

One number means real prioritisation
The what should we publish first argument used to take half a meeting because everyone ranked topics differently. One comparable score collapses it to the top three this week.

Refreshed as the engines change their minds
Engines do not hold citation preferences forever. A topic that scored eighty last month might score forty now. The score refreshes regularly.

Plugs into everything else you do
The score becomes the currency the suite runs on. Topic Planner ranks publishing order by it, and Competitor Tracking flags when a rival lowers it.
A live measurement, not a static guess
The score reflects what the engines do now, not what a keyword database thought six months ago. Live probing keeps the team on the current citation landscape.
No citation means an open door
When an engine answers without citing anyone, the slot is genuinely open and a strong answer can take it. The score surfaces these without digging.
Weak citations mean a door you can push through
When engines cite only weak competitors with thin authority, it is nearly as good as no citation. A strong answer can displace that placeholder fast.
One number means real prioritisation
The what should we publish first argument used to take half a meeting because everyone ranked topics differently. One comparable score collapses it to the top three this week.
Refreshed as the engines change their minds
Engines do not hold citation preferences forever. A topic that scored eighty last month might score forty now. The score refreshes regularly.
Plugs into everything else you do
The score becomes the currency the suite runs on. Topic Planner ranks publishing order by it, and Competitor Tracking flags when a rival lowers it.




8200+
Teams prioritising with real scores, not guesses.
Built for teams who publish when the door is open
Founders, content marketers, SEO specialists, agencies, and SaaS growth teams use Ranko's Opportunity Score to find topics where AI engines still want sources to cite, scored live zero to one hundred across all four engines.
Score
Engines
Measurement
Number
Asks every engine, measures the answer
Ranko asks each topic to ChatGPT, Claude, Perplexity, and Gemini as a real user would, then measures the answer: was anyone cited, and was the source strong or weak. The signal is live, grounded in what engines do now.
Everything the scoring engine ships with
A complete opportunity measurement toolkit in the same AEO platform you use, so you always know which doors are open.

Live Question Probing
Ranko asks each topic to ChatGPT, Claude, Perplexity, and Gemini as a real user would. Probing is live, so the score is current.

No Citation Detection
When an engine answers without citing anyone, the slot is open for a strong new answer. Ranko finds these wide open doors.

Weak Citation Detection
When engines cite only weak sources, the door is still pushable. Ranko scores citation strength by authority, depth, and frequency.

0 to 100 Opportunity Score
All measurements compress into one number, zero to one hundred per topic. Higher means a wider open door. Easy to sort.

Score Refresh as Engines Evolve
Engines change citation preferences. A topic that scored eighty last month might score forty now. The score refreshes often.

Suite Wide Prioritisation
The score is the currency Ranko runs on. Topic Planner ranks publishing by it, and Competitor Tracking flags when a rival lowers it.
Everything you need to know
Common questions on how the score is calculated, what counts as no versus weak citation, and refreshes.