Quiet when nothing changed.
Loud when something did.
The morning report only shows what changed overnight: new errors, score drops, orphan pages, broken data tags, position drops.

From overnight change to actionable alert in 4 steps
Five signals tracked nightly: new errors, score drops, orphan pages, broken data tags, position drops.

5 Overnight Signals
Overnight changes detected
Five specific signals get tracked every night, not vague anomaly detection that produces false alarms by Wednesday. New errors, score drops, orphan pages, broken data tags, position drops, each a known failure mode.
- New Errors
- Score Drops
- Orphan Pages
- Broken Tags · Position Drops

Threshold Control
The threshold filters the noise
The team controls how loud each signal is. A two-place position drop might be noise; a ten-place drop is not. A one-point score drop rarely matters; fifteen across a pillar page does. Each threshold is your call.
- Team Sets Threshold
- Per Signal
- Tightenable
- Loosenable
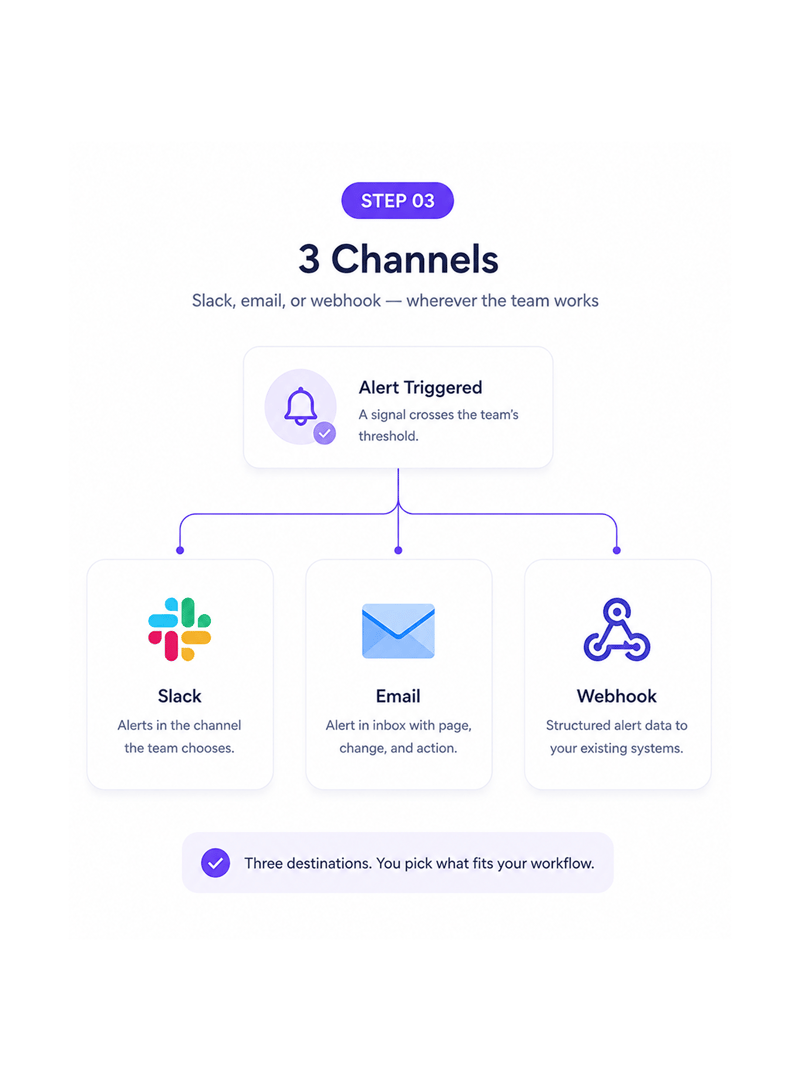
3 Channels
Slack, email, or webhook wherever the team works
When a signal crosses the threshold, the alert pushes where the team operates. Slack drops it into the channel you pick. Email lands with the page, the change, and suggested action. Webhook pushes structured data.
- Slack Channel
- Email Inbox
- Webhook
- Mix & Match

Tickets Attached
Fix from the alert, not a separate dashboard
Every alert arrives with a one-click button that pushes a ticket into the team's tracker: Asana, ClickUp, Trello, or Linear. Press once and the work appears in the tracker. No dashboard bouncing.
- One Click Ticket
- Asana · ClickUp
- Trello · Linear
- No Dashboard Bouncing
Six reasons the alerts get listened to
Once a team gets a Slack alert that fires only when something genuinely crossed a threshold they set, the trade-off ends.

Quiet days stay quiet, loud days get loud
Most alerting fires constantly until the team mutes it, or never fires until a problem has brewed for weeks. This stays quiet, then clear when needed.

The team sets the threshold, not the platform
Platform-decided thresholds are how most alerting fails; significance varies by site and season. The team sets them per signal to keep it useful.

Five specific signals tracked, not vague anomalies
Anomaly detection produces alerts no one can use. Five named signals, new errors, score drops, orphan pages, broken tags, position drops, are clear.

Slack, email, or webhook wherever the team works
Alerts that arrive where the team does not check get ignored. Routing to Slack, email, or webhook lands them where attention already is.

Alerts arrive when problems arrive, not the next quarter
A regression that started Tuesday and surfaces in next quarter's audit has cost ninety days. Real-time alerts collapse that to one morning.

Tickets attach automatically, so fixes flow into the tracker
Alerts the team must manually turn into tickets eventually go untranslated. One-click push into Asana, ClickUp, Trello, or Linear puts work in its place.
Quiet days stay quiet, loud days get loud
Most alerting fires constantly until the team mutes it, or never fires until a problem has brewed for weeks. This stays quiet, then clear when needed.
The team sets the threshold, not the platform
Platform-decided thresholds are how most alerting fails; significance varies by site and season. The team sets them per signal to keep it useful.
Five specific signals tracked, not vague anomalies
Anomaly detection produces alerts no one can use. Five named signals, new errors, score drops, orphan pages, broken tags, position drops, are clear.
Slack, email, or webhook wherever the team works
Alerts that arrive where the team does not check get ignored. Routing to Slack, email, or webhook lands them where attention already is.
Alerts arrive when problems arrive, not the next quarter
A regression that started Tuesday and surfaces in next quarter's audit has cost ninety days. Real-time alerts collapse that to one morning.
Tickets attach automatically, so fixes flow into the tracker
Alerts the team must manually turn into tickets eventually go untranslated. One-click push into Asana, ClickUp, Trello, or Linear puts work in its place.




14400+
Teams getting alerts they actually listen to
Built for teams who refuse alert fatigue and refuse silence at the same time
Founders wanting a quiet morning Slack, content leads tired of noise or missed regressions, search and AEO managers, agencies running ten clients with per-client routing, and ops leads all use these.
Push
Tracked
Threshold
Push
Five overnight change signals, threshold filtered
New errors, score drops, new orphan pages, broken page data tags, position drops. Five concrete signals tracked every night, each with a threshold the team controls. Quiet days stay quiet; loud days get loud.
Everything the alerts layer ships with
A complete alerting toolkit in your AEO platform: five overnight signals, a threshold each, and tickets.

Five Overnight Change Signals
New errors, score drops, orphan pages, broken data tags, position drops. Five signals tracked nightly, not vague anomaly detection.

Configurable Loudness Threshold
Each signal has a threshold the team controls. Position drop of two versus ten. Score drop of one versus fifteen. Adjust anytime.

Slack Channel Push
Alerts drop into the Slack channel you pick: team, specialist, or on-call. Each includes the page, the change, and a ticket button.

Email Notification
For teams who prefer email or stakeholders outside the channel, alerts land in the right inbox with context: page, signal, threshold.

Webhook Integration
For teams running incident infrastructure, alerts push as structured data to a webhook you configure, with the metadata it needs.

One Click Ticket Attached
Every alert has a one-click button that pushes a ticket into Asana, ClickUp, Trello, or Linear with page, signal, and fix included.
Everything you need to know
Common questions on what each signal catches, how thresholds work, bulk changes, muting, and the report.