Every draft is scored. Every
flagged section rewrites itself.
Every draft is scored against the top fifty web results and the full internal library. Sections over the threshold rewrite themselves.

From draft to verified original in 4 steps
The top fifty web results and Ranko's library are compared. Sections over the threshold rewrite to pass.

Top 50 Comparison
Top 50 web results pulled for comparison
Not the top three. Not just page one. The full top fifty web results for the article's topic, as the comparison corpus. Fifty is wide enough to catch overlap with sources the team never read and rivals.
- 50 Web Results
- Comprehensive Corpus
- Long Tail Covered
- Not Just Top 3
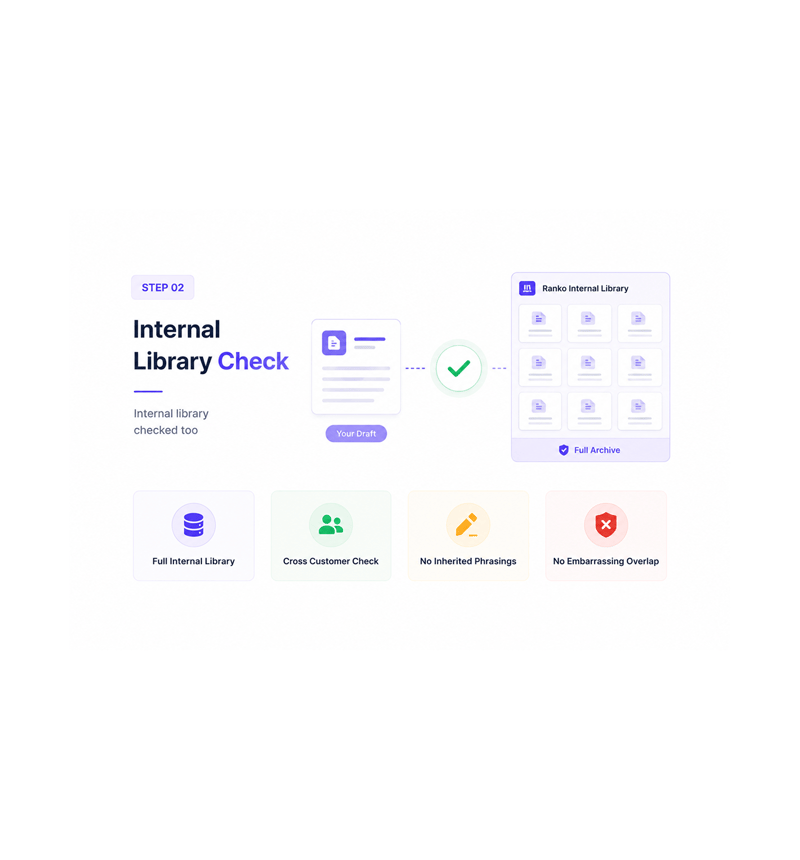
Internal Library Check
Internal library checked too
Most checkers only look at the open web, missing the worst overlap: two Ranko customers in the same category producing the same article. The internal library check compares every draft against the full archive.
- Full Internal Library
- Cross Customer Check
- No Inherited Phrasings
- No Embarrassing Overlap

Section Level Rewrite
Sections over threshold auto rewrite
Most checkers flag a problem and stop. Ranko flags it and fixes it. When a section crosses the threshold, it rewrites itself, preserving meaning, brand voice, and research while shifting phrasing to clear it.
- Section Level
- Auto Rewrite
- Meaning Preserved
- Voice Preserved

Iterative Recheck
Rewrite, recheck, rewrite, until it passes
A single rewrite is not always enough on dense topics. Ranko's check loops: rewrite the section, rescore against the top fifty plus the library, rewrite again if still too close, until it passes. No babysitting.
- Loop Until Pass
- No Babysitting
- Clear Escalation
- Ship Verified
Six reasons originality stops being a worry
Once articles are scored against the top fifty and the internal library, hoping the AI did not plagiarise is unacceptable.

Top 50 beats top 3
Most checks compare against a handful of obvious results and miss the long tail competitors. Top fifty is wide enough to catch the obscure matches.

auto rewrite, not just flagging
Other tools flag a problem and leave the rewrite to the team, so flags pile up. Ranko fixes what it flags. The section rewrites itself to pass.

Internal library check catches cross-customer overlap
The worst failure of the AI era is two teams on the same tool ending up with identical articles. The library check compares the full archive.

Section level, not whole article averages
An article can pass an overall average while one paragraph is a near match of a competitor's. Section level scoring catches what averages hide.

Originality is verified, not assumed
The originality of an AI article used to be a hope. Ranko replaces the assumption with verification: every flagged section is rewritten and rescored.

Editors stop fact-checking and start improving
Editors who spent half their time scanning drafts for near matches get those hours back. The check verifies freshness, so focus shifts to real work.
Top 50 beats top 3
Most checks compare against a handful of obvious results and miss the long tail competitors. Top fifty is wide enough to catch the obscure matches.
auto rewrite, not just flagging
Other tools flag a problem and leave the rewrite to the team, so flags pile up. Ranko fixes what it flags. The section rewrites itself to pass.
Internal library check catches cross-customer overlap
The worst failure of the AI era is two teams on the same tool ending up with identical articles. The library check compares the full archive.
Section level, not whole article averages
An article can pass an overall average while one paragraph is a near match of a competitor's. Section level scoring catches what averages hide.
Originality is verified, not assumed
The originality of an AI article used to be a hope. Ranko replaces the assumption with verification: every flagged section is rewritten and rescored.
Editors stop fact-checking and start improving
Editors who spent half their time scanning drafts for near matches get those hours back. The check verifies freshness, so focus shifts to real work.




12100+
Teams shipping content with verified originality, not assumed originality
Built for teams whose name is on the article when it ships
Founders who refuse to publish anything they would defend, content leads holding standards as volume rises, editors tired of policing AI, and compliance teams use the Originality Check.
Compared
Rewrite
Level
It Passes
Top 50 web results, full internal library
Every draft is scored against the top fifty web results, catching the long tail competitors smaller checks miss. The internal library is checked too, so it inherits no other Ranko work.
Everything the originality layer ships with
A verified originality toolkit. Top fifty web check, library check, section scoring, auto rewriting.

Top 50 Web Result Comparison
Every draft is scored against the top fifty web results, wide enough to catch the long tail competitors smaller samples miss.

Internal Library Cross-Check
Every draft is also scored against Ranko's full internal library, so your content does not overlap with another Ranko team's.

Section Level Similarity Scoring
Scoring happens at the section level, not the whole article, so it cannot pass an overall average while a paragraph is a near match.

Automatic Section Rewriting
When a section crosses the threshold, it rewrites itself: meaning, brand voice, and research kept, phrasing shifted to clear it.

Iterative Recheck Until Pass
A single rewrite is not always enough. Ranko's check loops: rewrite, rescore, rewrite, rescore, until it passes. No babysitting.

Originality Audit Trail
Every article ships with a full audit trail: sections checked, scores, rewrites, passing scores. Clean for compliance.
Everything you need to know
Common questions about what counts as too similar, why fifty results, the rewrite loop, and audit trails.