Workflows that survive
anything you throw at them
Enterprise grade execution on Temporal. Workflows survive crashes, scale to any volume, retry automatically, fall back locally.

From a running workflow to one you can trust with anything in 4 steps
Every workflow runs on a durable engine that checkpoints state after each step. Failures recover automatically.

Durable Execution
Workflows run on durable infrastructure
Every step of every workflow runs on a durable engine that captures its state the moment it completes. The crash that used to kill a long running workflow halfway through and leave a half finished job simply does not happen.
- Durable Engine
- Step Checkpointing
- Survives Crashes
- No Lost Work
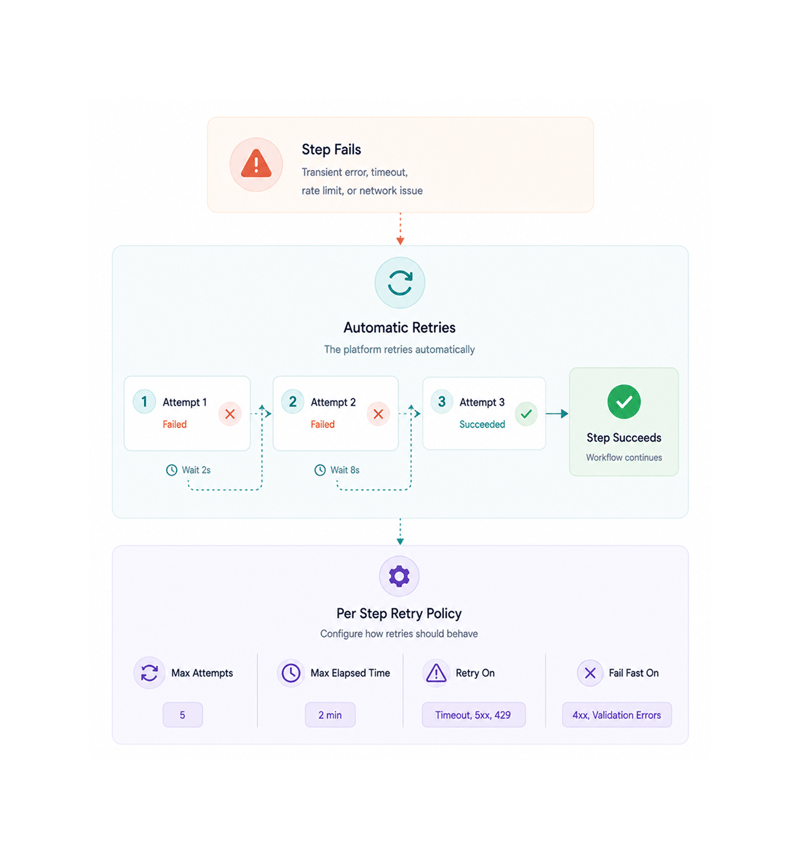
Automatic Recovery
Failures recover themselves
Transient failures, a service that stops responding, a network blip, a rate limit, retry automatically with sensible backoff. The policy is tunable per step, integration, or workflow. The midnight ticket becomes seconds of recovery.
- Automatic Retries
- Smart Backoff
- Per Step Policy
- Fail Fast When Needed

Full Execution History
Every execution is fully tracked
Every run keeps a complete history of every step that executed, the inputs received, outputs produced, retries, and decisions made. It is searchable and exportable, and any run can be replayed end to end. The audit trail is built in.
- Step Level History
- Full Replay
- Searchable & Exportable
- Audit Ready

Graceful Fallback
Falls back gracefully when needed
If the durable engine is temporarily unreachable, workflows fall back to local execution automatically so work keeps moving. Local execution still captures every step. When the engine returns, workflows resume on the next step.
- Local Fallback
- Work Keeps Moving
- History Reconciles Later
- Auto Return to Durable
Six reasons enterprise teams pick Revo
Once a team runs critical workflows on a durable engine, writing manual recovery code and praying at 3am looks unready for production.

Workflows survive crashes and outages
The horror story of a workflow dying halfway through and needing manual recovery stops. Every step is checkpointed, and every workflow continues where it left off.

Failures recover without anyone waking up
Transient errors, network blips, and rate limit hits, the small failures that used to wake engineers, get retried automatically. The on call rotation gets sleep back.

Scale grows with your business
The durable engine scales horizontally without losing state. A hundred runs a day to ten thousand to a million is a capacity change, not a re architecture.

Full audit trail for every execution
Every step of every run is captured with inputs, outputs, timing, retries, and result. Compliance reviews stop being archaeology and incidents stop being guesswork.

Replay any run from any point
Any execution replays against captured inputs to reproduce exactly what happened. Debugging incidents and validating fixes become deterministic exercises.

Graceful local fallback as a safety net
If the durable engine is unreachable, workflows do not stop. Local execution kicks in, history keeps being captured, and workflows resume on the next step.
Workflows survive crashes and outages
The horror story of a workflow dying halfway through and needing manual recovery stops. Every step is checkpointed, and every workflow continues where it left off.
Failures recover without anyone waking up
Transient errors, network blips, and rate limit hits, the small failures that used to wake engineers, get retried automatically. The on call rotation gets sleep back.
Scale grows with your business
The durable engine scales horizontally without losing state. A hundred runs a day to ten thousand to a million is a capacity change, not a re architecture.
Full audit trail for every execution
Every step of every run is captured with inputs, outputs, timing, retries, and result. Compliance reviews stop being archaeology and incidents stop being guesswork.
Replay any run from any point
Any execution replays against captured inputs to reproduce exactly what happened. Debugging incidents and validating fixes become deterministic exercises.
Graceful local fallback as a safety net
If the durable engine is unreachable, workflows do not stop. Local execution kicks in, history keeps being captured, and workflows resume on the next step.




6800+
Teams running mission critical workflows on
durable execution
Built for teams running
mission critical automation
Engineering leaders, platform teams, ops specialists, and finance teams handling regulated workflows use Revo where reliability is the default. Durable execution is the foundation, recovery and full history the rest.
Execution
Recovery
History
Fallback
Every step checkpointed, every failure recovered
The durable engine captures state after every step, so a crash, outage, or network blip never costs more than the last step. Failed steps retry with smart backoff and recover without anyone waking up.
Everything the execution engine ships with
A complete enterprise grade execution layer, built in. Durable execution on Temporal, smart retries, full history, scaling.

Durable Execution Powered by Temporal
Every workflow runs on a durable engine built on Temporal. State is captured after every step, so crashes never lose more than the last operation.

Automatic Retry with Smart Backoff
Transient failures retry automatically with exponential backoff. Policies are tunable per step, integration, or workflow, with attempt controls.

Full Execution History
Every step of every run is captured with inputs, outputs, timing, retries, and result. The history is searchable and exportable.

Step Level Checkpointing
Workflow state is captured after every step rather than only at the end, so a mid workflow crash loses at most the last in flight operation. Auto resume.

Horizontal Scale Without State Loss
The durable engine scales horizontally as volume grows. A hundred runs a day to ten thousand to a million is a capacity change, not re architecture.

Graceful Local Fallback
If the durable engine is temporarily unreachable, workflows fall back to local execution, then return to durable on the next step.
Everything you need to know
Questions about durable execution, retries, history, scaling, replay, and fallback.